in和exsits优化、count(*)查询优化
一、in和exsits优化
原则:小表驱动大表,即小的数据集驱动大的数据集
in:当B表的数据集小于A表的数据集时,in优于exists
select * from A where id in (select id from B)
#等价于:
for(select id from B){
select * from A where A.id = B.id
}exists:当A表的数据集小于B表的数据集时,exists优于in
将主查询A的数据,放到子查询B中做条件验证,根据验证结果(true或false)来决定主查询的数据是否保留
select * from A where exists (select 1 from B where B.id = A.id)
#等价于:
for(select * from A){
select * from B where B.id = A.id
}#A表与B表的ID字段应建立索引
1、EXISTS (subquery)只返回TRUE或FALSE,因此子查询中的SELECT * 也可以用SELECT 1替换,官方说法是实际执行时会忽略SELECT清单,因此没有区别
2、EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比
3、EXISTS子查询往往也可以用JOIN来代替,何种最优需要具体问题具体分析
二、count(*)查询优化
‐‐ 临时关闭mysql查询缓存,为了查看sql多次执行的真实时间
mysql> set global query_cache_size=0; mysql> set global query_cache_type=0; mysql> EXPLAIN select count(1) from employees; mysql> EXPLAIN select count(id) from employees; mysql> EXPLAIN select count(name) from employees; mysql> EXPLAIN select count(*) from employees;
注意:以上4条sql只有根据某个字段count不会统计字段为null值得数据行
四个sql的执行计划一样,说明这四个sql执行效率应该差不多。
如果字段有索引:count(*)≈count(1)>count(字段)>count(主键 id) //字段有索引,count(字段)统计走二级索引,二
级索引存储数据比主键索引少,所以count(字段)>count(主键 id)
字段无索引:count(*)≈count(1)>count(主键 id)>count(字段) //字段没有索引count(字段)统计走不了索引,
count(主键 id)还可以走主键索引,所以count(主键 id)>count(字段)
阿里巴巴Mysql规范
1.单表行数超过500万行或单表容量超过2GB,才推荐进行分库分表。
说明:如果预计三年后得数据量根本达不到这个级别,请不要在创建表时就分库分表。
索引规约
1【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生
2. 【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。说明:即使双表 join 也要注意表索引、SQL 性能.
4【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
sql语句
1.【推荐】in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个之内。(数据太多不一定走索引,太少也不一定走索引)
2.【参考】因国际化需要,所有的字符存储与表示,均采用 utf8 字符集,那么字符计数方法需要注意。说明: SELECT LENGTH("轻松工作"); 返回为 12 SELECT CHARACTER_LENGTH("轻松工作"); 返回为 4 如果需要存储表情,那么选择 utf8mb4 来进行存储,注意它与 utf8 编码的区别。
补充:MySQL数据类型选择
选择正确的数据类型,对于性能至关重要。一般应该遵循下面两步:
(1)确定合适的大类型:数字、字符串、时间、二进制;
(2)确定具体的类型:有无符号、取值范围、变长定长等。
1、数值类型
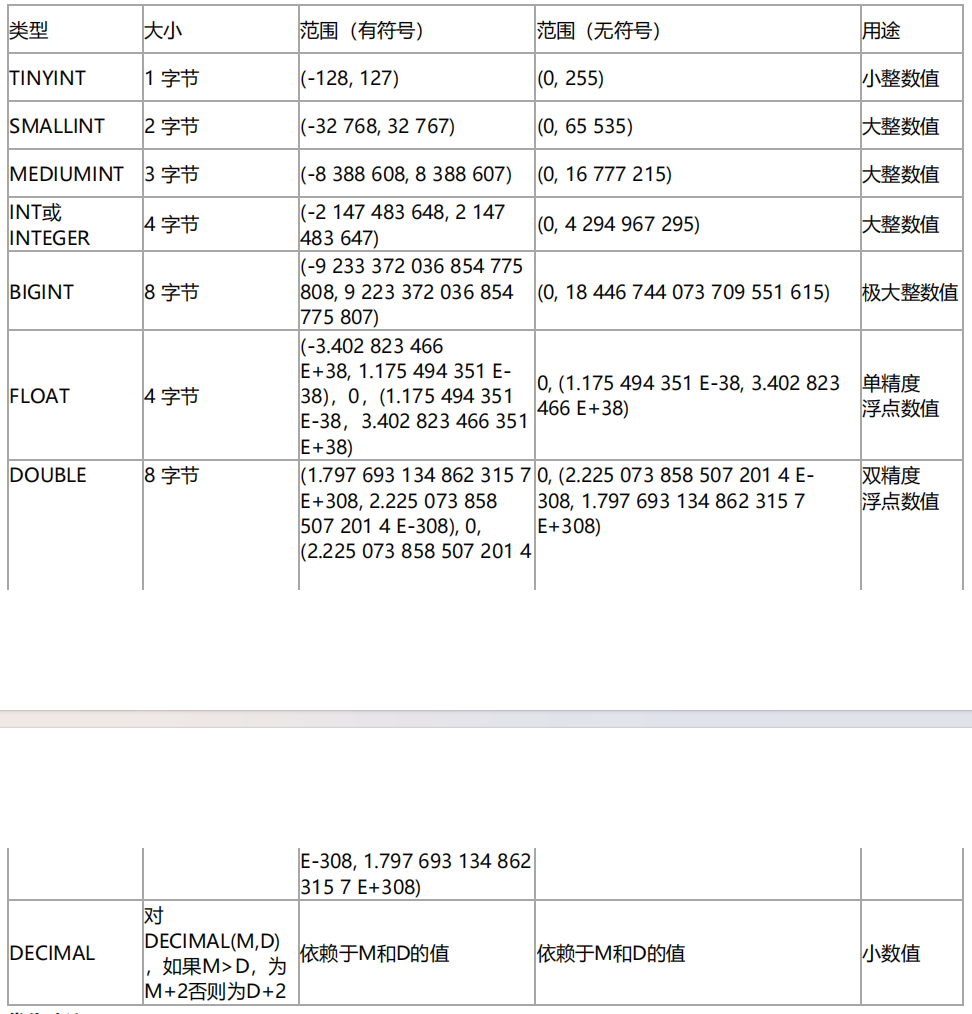
1优化建议:
1如果没有负数的话,建字段的时候选择无符号(比如id字段),容量可扩大一倍。
2. 建议使用TINYINT代替ENUM、BITENUM、SET。
3. 避免使用整数的显示宽度,也就是说,不要用INT(10)类似的方法指定字段显示宽度(没用,id` TINYINT(2) UNSIGNED ZEROFILL 加了零填充才有用 就类似0000000001),直接用INT。
4. DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。但是在使用DECIMAL类型的时候,注意长度设置。
5. 建议使用整形类型来运算和存储实数,方法是,实数乘以相应的倍数后再操作。
6. 整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT
2、日期和时间
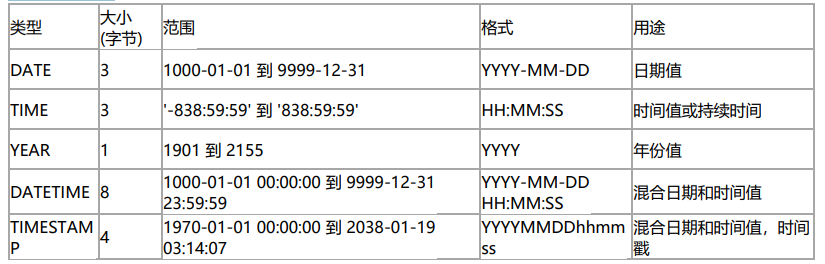
优化建议:
1如果是大公司用DateTime,如果是小公司用Timestamp,因为占用空间小,也不一定能到2038年,过了这一年就得改字段。
3、字符串
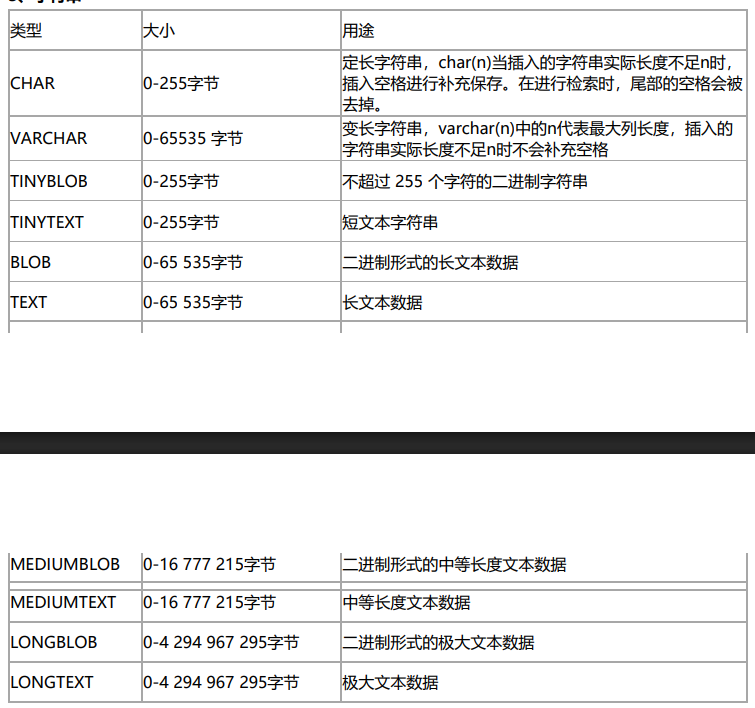
优化建议:
1. 尽量少用BLOB和TEXT,如果实在要用可以考虑将BLOB和TEXT字段单独存一张表,用id关联.
2字符串的长度相差较大用VARCHAR;字符串短,且所有值都接近一个长度用CHAR
本文原创,转载必追究版权。

