Explain工具介绍:
使用explain关键字可以模拟优化器执行sql语句,分析查询语句的或是结构的性能瓶颈。在select语句之前增加explain关键字,Mysql会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条sql。
注意:如果from中包含子查询,仍会执行该子查询,将结果放入临时表中
explain语句 后面跟sql语句:
explain select * from actor;
explain两个变种(Mysql5.7以上不需要用变种了)
(Mysql5.7以下版本需要变种显示partitions或filtered两个字段,5.7以上explain直接就有partitions和filtered这两个字段了):
1.explain extended:会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可以得到优化后的查询语句,从而看出优化器优化了什么
filtered 列,是一个百分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
explain extended select * from film where id =1;
show warnings 命令可以得到优化后的查询语句。
2explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
explain结果列:
1.id :id列的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的。
最大值先执行,id列越大执行优先级越高,id相同则从上往下执行,id为Null最后执行。
2.select_type 查询类型:
simple:简单查询,查询语句不包含子查询和union
primary:复杂查询,最外层的select
derived:衍生查询(from后面的子查询语句)、
subquery:子查询,包含在 select 中的子查询(不在 from 子句中)
union:在 union 中的第二个和随后的 select
3.table表名
4.prtitions 如果查询是基于分区表的话,partitions 字段会显示查询将访问的分区
5.type关联类型或访问类型:system只查询有一条数据、const常量查询一样简单、eq_ref:主键或唯一索引关联,只返回一条记录,ref不使用唯一索引,而是使用普通索引或者唯一索引的前缀,可能会找到多个符合条件的行。range:范围查找。index:扫描全索引就能拿到结果集,一般扫描某个二级索引(查整表无条件时优先使用二级索引查询,因为二级索引小) ,all:全表扫描,扫描聚集索引的所有叶子节点。
优先级:system>const>eq_ref>ref>range>index>ALL.一般需要保证达到range级别,最好达到ref
ref与index的区别:ref是从根节点开始查找;index是全索引扫描(从叶子节点查找)。
index与all的区别:二级索引比主键索引效率高,二级索引叶子节点只有 主键值,如果要查其他字段还要回表用主键索引查。All是走的主键索引的叶子节点
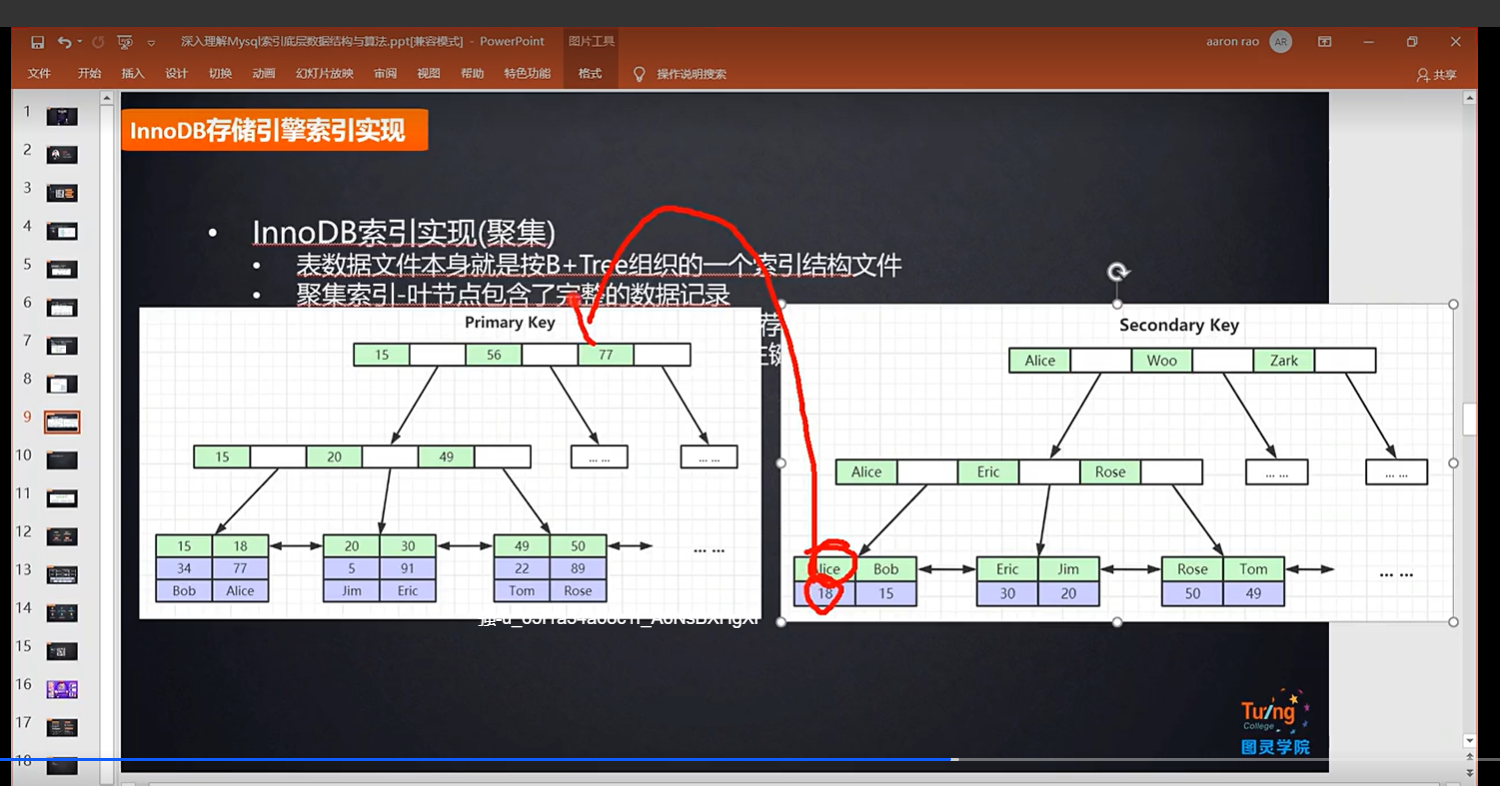
6.possible_key:可能会用到的索引
7.key:真正执行用到的索引
8.ken_len:使用的key的长度,比如联合索引的话,可以查看用了几个索引的长度。
9ref:查询条件的 字段值类型或字段
10.rows:计算这条sql语句可能要扫描多少行(预估值,不一定是实际值)。
11.extra列:
如果是Using index覆盖索引,不会回表,直接在二级索引就查到结果了(也就是key值直接能查到)。
Using filesort:文件排序,没有走索引。
using where。直接用where语句就找打到结果,没走索引,key没有值
using index condition。不完全被索引覆盖,where条件里有范围查询
using temporary。用了临时表---可以优化成using index。给查询的字段加上索引即可
如果为空,说明还要回表查主键 索引,查询除了id外的其他字段数据(走完key值,还要回表)。
mysql优化:
1索引列不要加函数,有函数不走索引(因为函数后的值在索引树里是无序的或是没有的)。
2.尽量使用覆盖索引,减少使用select *
3.where 使用!= 的 不走索引,导致全表扫描(不一定);
4.联合索引中 有字段使用了范围查找,范围条件右边的列不走索引。
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';
5.is null ,is not null 一般情况下也不走索引。
6.like 模糊查询,以通配符%开头的会使索引失效,导致全表扫描。
7.字符串不加单引号,索引失效。或是关联字段类型不同,会导致索引失效。
8.少用or 或者in,不一定走索引。在数据量大的时候会走索引,表记录不多的时候会走全表扫面。mysql内部优化器会根据检索比例、表的大小等因素整体评估是否用索引,范围查询优化
9.联合索引,如果第一个字段如果是范围查询不走索引,mysql认为数据量大,宁愿走all。范围查询放在中间就走了。如果是>=又走了(前提是不能在第一个字段)。
比如:explain select * from employees where name > 'LiLei' and age = 22 and position = 'manager'
强制走索引,不一定快:explain select * from employees force index(idx_name_age_position) where name > 'LiLei' and age = 22 and position = 'manager'
关闭查询缓存量:set global query_cache_size = 0;set global query_cache_type = 0;
索引下推:mysql 5.6以后 like查询开头的字段都用到了索引下推。
