深入理解mysql索引底层数据结构及算法
一、索引的本质:帮助Mysql 高效获取数据的排好序的数据结构。
二、索引数据结构:二叉树、红黑树、Hash表、 B-Tree
二叉树:不适合递增的列。(链表式,查找次数多。右边比左边大)
红黑树:本质是二叉树,二叉平衡树(比二叉树优化了点)
Hash表(基本不用):hash算法,MD5基于此,仅能满足=,in,不支持范围查询。
B-Tree:
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列
三、mysql使用的索引的数据机构是: B+Tree
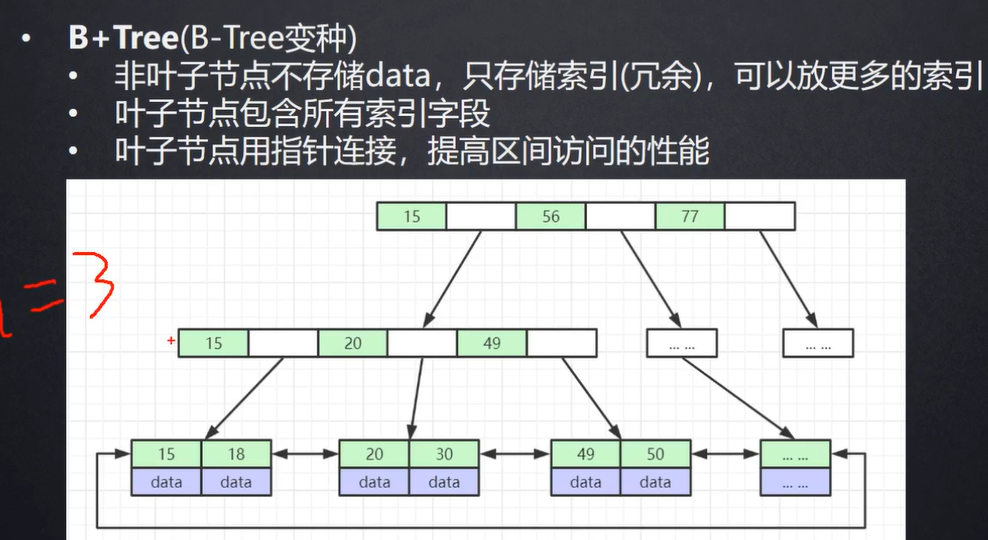
B-Tree与 B+Tree的区别:
1.非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。tree结构从左到右依次递增
2.叶子节点包含所有的索引字段。
3.B+Tree叶子节点有双向指针,方便范围查找。
四.表的存储引擎索引:
MylSAMl存储引擎索引也是存到磁盘上的,一般在mysql的安装文件data里面。索引和数据是分开的,通过索引对应的磁盘文件地址,再通过磁盘文件地址找完整的数据 。
innoDB存储引擎
聚集索引:叶子节点索引下面存的是完整数据。(文件在ibd文件中)
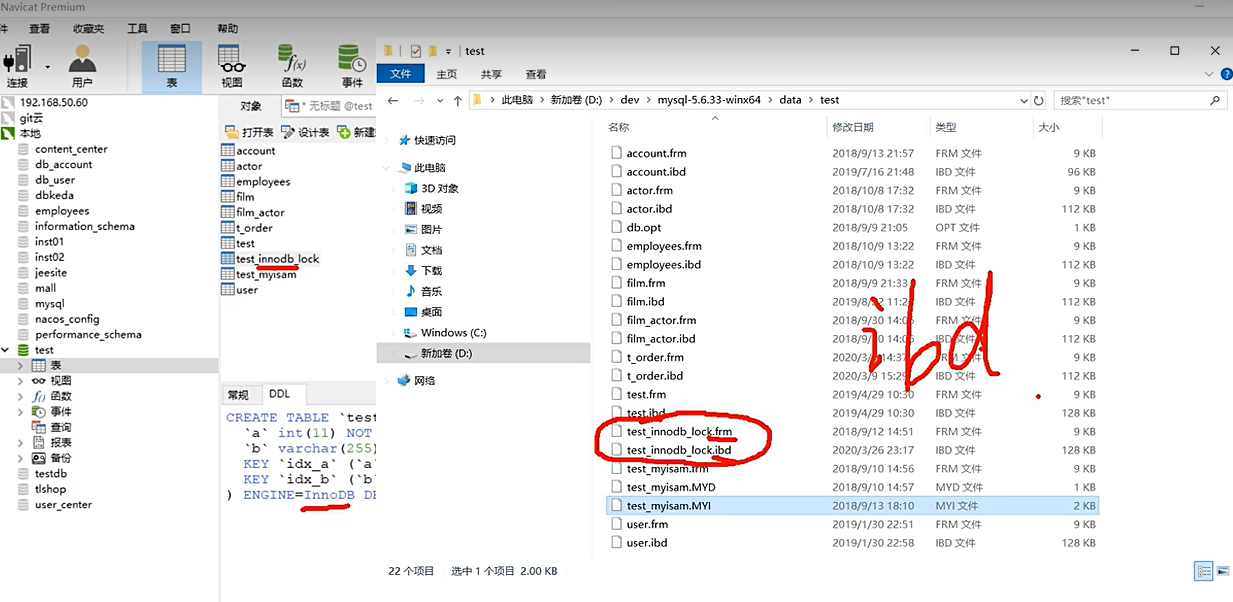
建议innoDB表要建主键,并使用整型。容易比大小,字符串还得逐个比对。
聚集索引和非聚集索引(还需要回表)那个更快?聚集更快。
如果用分库分表,用 雪花算法比较好。
五、联合索引:遵循最左前缀原则。
本文原创,转载必追究版权。